
在程序开发中,我们常遇到用树型结构来表示某些数据间的关系,如企业的组织架构、商品的分类、操作栏目等,目前的关系型数据库都是以二维表的形式记录存储数据,而树型结构的数据如需存入二维表就必须进行Schema设计。
最近对此方面比较感兴趣,专门做下梳理,如下为常见的树型结构的数据:

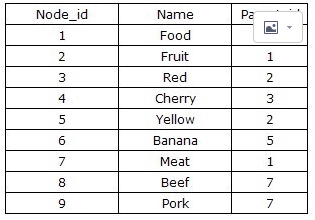
其中最简单的方法是:Adjacency List(邻接列表模式)。简单的说是根据节点之间的继承关系,显现的描述某一节点的父节点,从而建立二位的关系表。表结构通常设计为{Node_id,Parent_id},如下图:
使用连接表的大致代码:
1 |
|
对整个结构的根节点(Food)使用这个函数就可以打印出整个多级树结构,由于Food是根节点它的父节点是空的,所以这样调用: display_children(”,0)。将显示整个树的内容。如果你只想显示整个结构中的一部分,比如说水果部分,就可以这样调用:
display_children(‘Fruit’,0);
几乎使用同样的方法我们可以知道从根节点到任意节点的路径。比如 Cherry 的路径是 ”Food >; Fruit >; Red”。 为了得到这样的一个路径我们需要从最深的一级”Cherry”开始, 查询得到它的父节点”Red”把它添加到路径中, 然后我们再查询Red的父节点并把它也添加到路径中,以此类推直到最高层的”Food”
以下是代码:
1 |
|
如果对”Cherry”使用这个函数:print_r(get_path(‘Cherry’)),就会得到这样的一个数组了:
1 | Array |
这种方案的优点很明显:结构简单易懂,由于互相之间的关系只由一个parent_id维护,所以增删改都是非常容易,只需要改动和他直接相关的记录就可以。缺点当然也是非常的突出:由于直接地记录了节点之间的继承关系,因此对Tree的任何CRUD操作都将是低效的,这主要归根于频繁的“递归”操作,递归过程不断地访问数据库,每次数据库IO都会有时间开销。举个例子,如果想要返回所有水果,也就是水果的所有子孙节点,看似很简单的操作,就需要用到一堆递归。当然,这种方案并非没有用武之地,在树的层级比较少的时候就非常实用,在邻接列表模式的基础上还可以拓展的是平面表,区别是将节点的level和当前节点的顺序也放入表中,比较适合类似评论等场景,具体的表结构类似这样,这里就不再深入阐述。

参考链接:
● http://salman-w.blogspot.com/2012/08/php-adjacency-list-hierarchy-tree-traversal.html
● https://packagist.org/search/?tags=adjacency%20list
转自https://www.biaodianfu.com/adjacency-list.html
作者:标点符

