
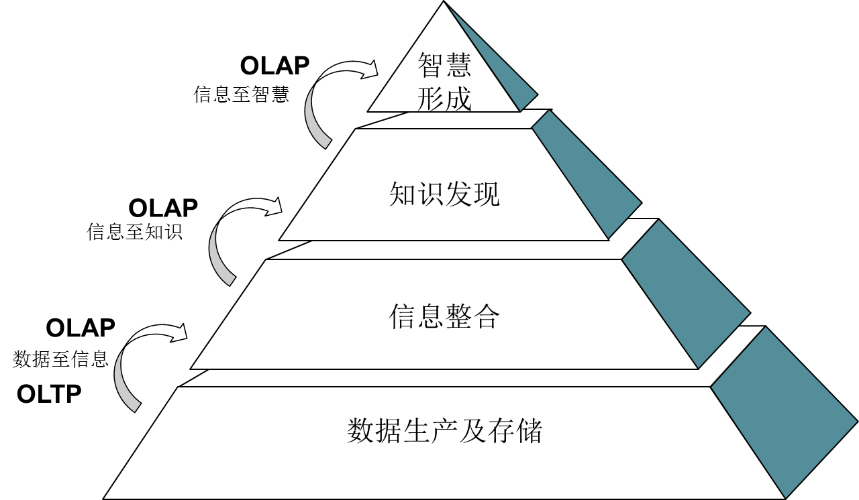
按数据处理方式及使用目标,企业级IT系统可分为OLTP和OLAP系统。简而言之,OLTP系统生产数据,OLAP系统加工数据。从数据到智慧的转换金字塔上看,OLTP系统实现了底层的数据产生和存储以及面向事务的信息整合,在这之上的各层就要依赖OLAP系统了。OLAP概念源自决策支持系统(DSS),企业中的数据仓库、数据集市、统计报表、驾驶舱、数据挖掘等都属于OLAP体系。其中,数据仓库和数据集市主要实现信息整合,一般统称为数据整合平台。统计报表、驾驶舱、数据挖掘进一步利用数据整合平台的成果,帮助用户发现知识并最终形成智慧。
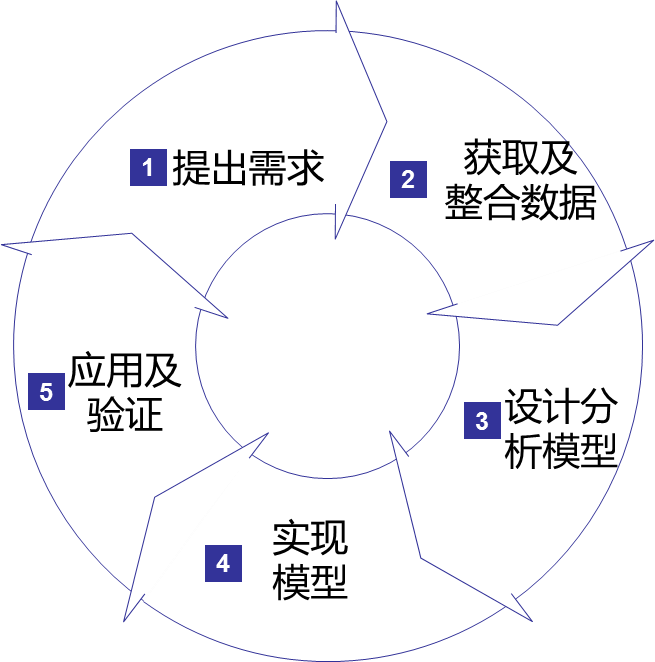
OLAP系统的主要用户是分析人员和管理人员,目标是支持管理决策,依据是企业生产经营过程中产生的全量数据,是一个按目标使用场景对数据进行加工、利用的过程。这过程一般可以划分五个阶段:业务部门定义需求;IT部门根据需求获取并整合相关数据;IT部门根据需求设计分析模型;IT部门开发实施并发布;业务部门应用并衡量实际成效。在传统的数据基础和技术环境下,这个周期可能要经历较漫长的时间。还在建设OLAP体系的情况自不必多说,即便已建成OLAP体系统,要及时响应业务部门的需求也是较困难的,而且很有可能最终的交付质量不能达到需求方的预期。
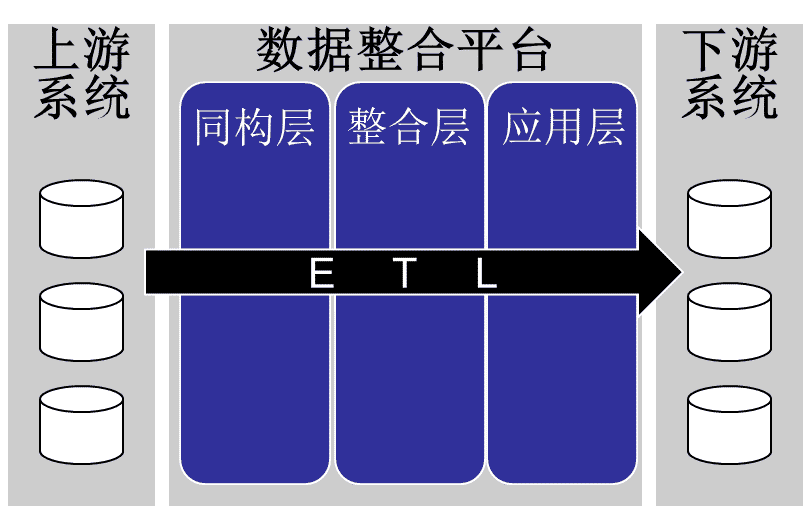
下图是目前较常见的OLAP体系简图,上游系统指那些OLTP系统,是数据源。数据整合平台包括ODS、数据仓库、数据集市等,主要实现数据整合。下游系统指那些利用数据整合平台成果的系统,包括统计报表、驾驶舱、数据挖掘等。其中,数据整合平台承上启下,在整个OLAP体系中非常重要。按照目前较普遍的架构,从上游到下游的数据流向,至少分为同构层、整合层、应用层。其中同构层在模型上基本与上游接入数据源基本保持一致,整合层一般会采用高范式模型进行数据整合,应用层面向下游具体应用采用星型模型。这个架构是在Inmon帮和Kimball派十几年如一日的不断撕逼和妥协中演进出来的,应该是一种最佳实践。但随着互联网+大数据时代到来,对数据应用有着更高效、更深入的要求,这种架构本身固有的缺点被不断放大。
开发周期长
为了避免因上游系统接入模型的变化而导致数据整合平台模型的被动调整,整合层建模时一般会采用较高范式实现高内聚、低耦合,ER实体较多、关系复杂。这样就增加了ETL设计、开发以及测试的复杂度,同时ETL程序执行效率也低。业务部门提出的需求,IT首先由下至上逐层对模型进行分析,即便只需在应用层开发,基于上述原因也需要一周以上。如果涉及要改动整合层,开发周期要一个月左右,业务部门显然是不能接受的。最后的结局不用猜都知道,苦逼的程序猿只能再一次强睁熊猫眼天天加班赶工。但是故事并没有到此结束,马上一个意想不到但细细想想又是顺理成章的伴生问题发生了。
架构迅速变坏
在日复一日的高压下,程序猿只能另辟蹊径为自己减负。既然工作量是由于数据模型和层次的复杂性引起的,那最有效的减少工作量的方法无非就是:1、绕过整合层,数据直接从同构层到应用层。2、还是从通过整合层,但使用面向应用的自建模型。无论哪种方法,都使整合层形同虚设,从同构层到应用层形成一个个数据井道。虽然单个开发任务的开发时间缩短了,但各数据井道之间无法复用,所以总的开发时间绝对要更多,而且后期的维护工作将是一场噩梦。

效率低
架构变坏后,数据一致性无法保证,大量数据重复存储,大量指标重复计算,ETL作业数急剧上升,数据整合平台效率自然会越来越差。即便架构还能保持,但随着时间的推移,数据量及业务需求不断增加,架构上倾向分割出更多的层次,以便实现更多的复用。随着层次的增加,数据迁移的路径就变长了,长久以往也难逃低效率的宿命。
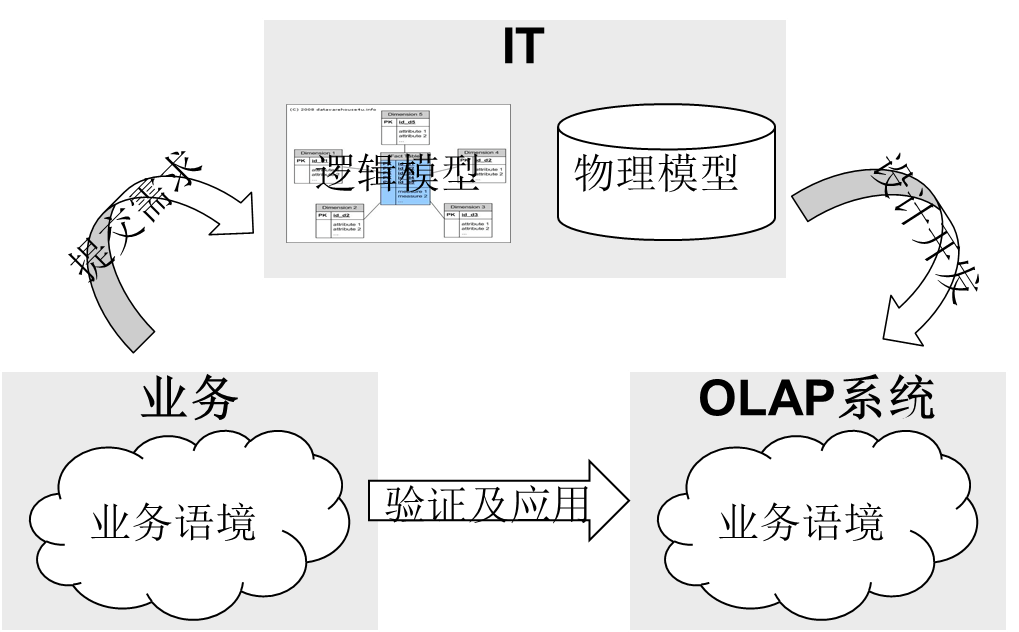
再回顾下OLAP数据应用的五个阶段,从业务提出需求到业务应用验证形成闭环,这过程是由IT导向推动的,IT首先与业务讨论分析需求,在业务模型层面中达成共识,然后再映射到系统模型,实现对来自上游系统的数据进行加工处理,最后通过OLAP系统将结果在业务语境中展现给用户,之前讨论的所有弊病都此有关。而对于像银行、保险等发展较成熟的行业,其业务语境、模型是较稳定的,支持业务开展的上游IT系统的系统模型也应该是相对稳定的,因此业务模型和系统模型间能形成较稳定的映射关系。这样只要能达到足够细的粒度,就能实现操纵业务模型来改变系统模型的目的。而业务模型又能被业务所能理解,因此这个闭环过程就可以完全由业务导向不需要IT的参与,整个过程可以简化为:业务设计模型,业务应用验证。
文/season7(简书作者)
原文链接:http://www.jianshu.com/p/d55d8eeac219

