
有没有遇到过在一个没有主键标志的表里存了重复的数据行,要把重复的行删掉保留一行的情况呢?我们可以设置SQL Server的ROWCUNT变量来限制影响的数据行数,默认的数据值是0,代表所有行,但是这个值可以在运行SQL语句之前进行设定。
咱们首先建个测试用的表,插入几条条记录。
CREATE TABLE dbo.duplicateTest
(
[ID] [INT] ,
[FirstName] [VARCHAR](25) ,
[LastName] [VARCHAR](25)
)
ON [PRIMARY];
INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith')
INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones')
INSERT INTO dbo.duplicateTest VALUES(3, 'Karen','White')
INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith')
INSERT INTO dbo.duplicateTest VALUES(2, 'Dave','Jones')
INSERT INTO dbo.duplicateTest VALUES(1, 'Bob','Smith')
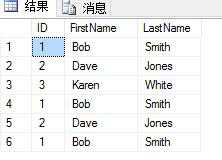
表内数据如下:
SELECT * FROM dbo.duplicateTest
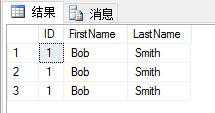
我们要找到Bob Smith的记录可以用以下语句:
SELECT * FROM dbo.duplicateTest WHERE ID = 1 AND FirstName = 'Bob' AND LastName = 'Smith'
找到三行数据
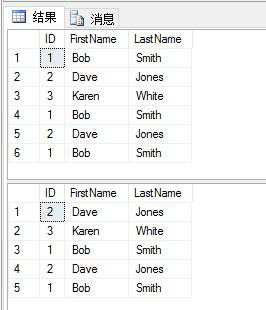
在SQL Server 2000 和 2005上我们可以使用SET ROWCOUNT 命令来限制一条语句作用的行数,设置为1我们就可以删除一条重复的记录了。删除前与删除后的对比如下:
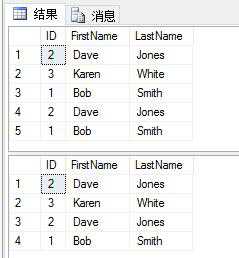
在SQL Server 2005上,我们也可以用TOP命令。像下面这样:
SELECT * FROM dbo.duplicateTest
DELETE TOP(1) FROM dbo.duplicateTest WHERE ID = 1
SELECT * FROM dbo.duplicateTest
删除前与删除后的对比如下:
总结
- 1、这个方法可以在表中没有明显标志字段来区分每一行的情况,但也有局限,如果一个表中不知道每行记录都有多少行重复的记录,就不能用了,TOP(1)也只是删除重复行中的一行。
- 2、如果明确知道表里每行记录都有2行、3行……重复的记录,倒是个不错的选择。
- 3、如果表里有个ID自增长的字段,就可以采用删掉重复行保留ID最小的那个行的方法了。
- 4、如果表里没有ID自增长的字段,又不知道每行有多少条重复记录,重复记录行都一样,那还是先把记录DISTINCT出来存到临时表里,清空原表,再把临时表的数据插入原表,这样应该是最省事的了。

