使用Markdown写东西有时需要插入表格,方式有两种:
- 1.使用Markdown的表格语法
- 2.使用html的
<table>标签来创建表格
但是某些Markdown编辑器中使用<table>标签会出现表格前有空行的情况。
No results found
使用Markdown写东西有时需要插入表格,方式有两种:
<table>标签来创建表格但是某些Markdown编辑器中使用<table>标签会出现表格前有空行的情况。
ORACLE物化视图(MATERIALIZED VIEW)有自动提交刷新和手动刷新两种刷新方式,每种刷新方式下有增量刷新(FAST)、全量刷新(COMPLETE)、系统自动判断(FORCE)三种刷新方法。一般而言,增量刷新理论上是比全量刷新要快一些的,但是我发现某些情况下增量刷新将导致基表提交后延迟严重,下面将做一些测试。
对物化视图的状态等信息进行查询,监控和管理时,需要对系统视图进行查询,以下列出了常用的物化视图状态、依赖关联,批量维护时能用到的查询语句,根据具体情况进行适当修改。
当需要对物化视图的状态等信息进行查询,监控和管理时,就要用到相关的系统元数据表了,本文介绍了Oracle物化视图相关的元数据系统视图的表结构,这些视图有:ALL_VIEWS,DBA_MVIEWS,USER_MVIEWS,ALL_MVIEW_ANALYSIS,DBA_MVIEW_ANALYSIS,USER_MVIEW_ANALYSIS,ALL_MVIEW_AGGREGATES,DBA_MVIEW_AGGREGATES,USER_MVIEW_AGGREGATES,ALL_MVIEW_REFRESH_TIMES,DBA_MVIEW_REFRESH_TIMES,USER_MVIEW_REFRESH_TIMES,ALL_MVIEW_JOINS,DBA_MVIEW_JOINS,USER_MVIEW_JOINS,ALL_MVIEW_KEYS,DBA_MVIEW_KEYS,USER_MVIEW_KEYS,ALL_MVIEW_LOGS,DBA_MVIEW_LOGS,USER_MVIEW_LOGS。
快速刷新的物化视图创建比较麻烦,限制条件比较多,本文参考Oracle 11g 11.2版本官方文档,总结一般情况、含有联接、含有聚合计算、UNION ALL等情况下的限制条件。
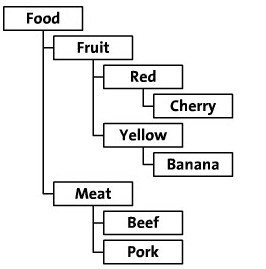
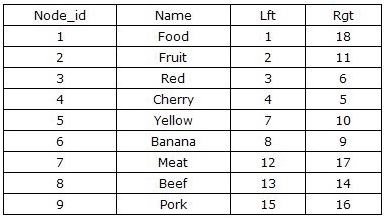
前面的一篇文章介绍了左右值编码,不知道大家注意到了没有,如果数据庞大,每次更新都需要更新差不多全表,效率较低没有更好的方式?今天我们就来研究下区间嵌套法。
区间嵌套法原理
如果节点区间[clft, crgt]与[plft, prgt]存在如下关系:plft <= clft and crgt >= prgt,则[clft, crgt]区间里的点是[plft, prgt]的子节点。基于此假设我们就可以通过对区间的不断的向下划来获取新的区间。举例:如果在区间[plft, prgt]中存在一个空白区间[lft1, rgt1],如果要加入一个[plft,lft1]、[rgt1,prgt]同级的区间,只需插入节点:[(2*lft1+rgt1)/3, (rgt1+2*lft)/3]。在添加完节点后我们还留下[lft1,(2*lft1+rgt1)/3]和 [(rgt1+2*lft)/3,rgt1]两个空余的空间用来添加更多的子节点。
在基于数据库的一般应用中,查询的需求总要大于删除和修改。为了避免对于树形结构查询时的“递归”过程,基于Tree的前序遍历设计一种全新的无递归查询、无限分组的左右值编码方案,来保存该树的数据。
将Closure Table翻译成闭包表不知道是否合适,闭包表的思路和物化路径差不多,都是空间换时间,Closure Table,一种更为彻底的全路径结构,分别记录路径上相关结点的全展开形式。能明晰任意两结点关系而无须多余查询,级联删除和结点移动也很方便。但是它的存储开销会大一些,除了表示结点的Meta信息,还需要一张专用的关系表。
在程序开发中,我们常遇到用树型结构来表示某些数据间的关系,如企业的组织架构、商品的分类、操作栏目等,目前的关系型数据库都是以二维表的形式记录存储数据,而树型结构的数据如需存入二维表就必须进行Schema设计。
宽表从字面意义上讲就是字段比较多的数据库表。通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表。由于把不同的内容都放在同一张表存储,宽表已经不符合三范式的模型设计规范,随之带来的主要坏处就是数据的大量冗余,与之相对应的好处就是查询性能的提高与便捷。这种宽表的设计广泛应用于数据挖掘模型训练前的数据准备,通过把相关字段放在同一张表中,可以大大提高数据挖掘模型训练过程中迭代计算时的效率问题。
————百度百科
1 | sp_addextendedproperty |
今天来谈谈,写博客对我的益处,说起写博客,其实我写博客的时间不长,也就10来个月时间;之前工作的时候,看到同事每天晚上写博客,当时觉得很奇怪,就觉得写这个东西,非常浪费时间,自己知道的好的技术或者是好的技术解决思路,如果分享出去,不是被别人学去了吗等等一系列问题.
等写了一段时间博客时,慢慢发现,其实之前的担心的完全没必要,你会的东西,精通的知识,即使分享出去,别人也未必能学的会,即时要学会学透,也是要花费时间和精力的,所以这种担心我们大可不必.人还是要有点分享和谦虚精神的,仅仅是这种只进不出的思想,我想你也很难有的发展!那么写博客10来个时间里,通过写博客给自己带来了哪些方面的提升呢?下面我就结合自己经力来给大家做个详细的总结.

还有一天,购买的服务器就要到期了,并没有续期的打算,意味着在服务器上运行的这个Solo博客就停掉了。其实也没有什么大不了的事情,只是想来这一路没有为自己能够坚持而愧疚。
今天饶有兴趣的了解了PKM,深感做好PMK还真不是件容易事。从小到大,我们都说学习知识,也就说明知识并不会简单的成为自己的东西,知识在成为自己的之前的身份是信息。从信息转化为自己的知识是有一个过程,这就是自己的思考、总结、应用以及分享。
所以也就不难理解,从小到大,我们在学习之后要做练习,学是我们接收信息的过程,习则是引导我们进行思考然后运用的过程。现在回想起来,这一路学习知识的过程总少了一点什么,是的,我们做了很多练习,背了很多东西,然而知识在成为了自己的之后却很快又溜走了,时间长了就遗忘了是一个因素,另一个重要的因素是没有将知识管理起来的思想,他们大多成了我们脑海里的碎片,彼此没有关联。

你朋友圈的第一条状态是什么时间?
我的第一条状态来自2012年12月6日,我是个比较愚钝的人,那天之前我用的还是诺基亚E63,红色的全键盘手机,大学男朋友送的,上学时候超酷。
Play Framework是啥?引用下百度百科的说法:
Play!是一个full-stack(全栈的)Java Web应用框架,包括一个简单的无状态MVC模型,具有Hibernate的对象持续,一个基于Groovy的模板引擎,以及建立一个现代Web应用所需的所有东西。
当然,这个介绍是比较旧的,对于老版本的Play!,这么说没毛病。进入Play!官网看看,满眼的绿啊,有一股清新之感呐。版本都到2.5.8了。追溯1.0版本都是在2010.07.28发布的,到现在已经有6年时间了。
使用PowerDesigner生成数据库脚本时报 Constraint name uniqueness 错误: